いよいよデータベースの構築です。データベースの設計を後から変更するのは難しいことですから、最初にきちんとした計画をたてましょう。
正規化とは?
正規化の概要
リレーショナルデータベースには、リレーションの『正規化』という、データベースを設計、実装する際の重要なテクニックがあります。適切にリレーションの正規化が行われたデータベースは、データの一貫性が確保され、効率的なデータアクセスが行われます。データの安全性と使用時のパフォーマンスを向上させることができる正規化は、ぜひマスターしておきたいテクニックです。
Microsoft Excelのような表計算ソフトで表を作成した場合、リレーションのことを考慮する必要が無いので、通常は正規化が行われていない、非正規形になります。
たとえば、購入履歴をExcelで記録する際は、下記のような非正規形のテーブルで問題ありません。
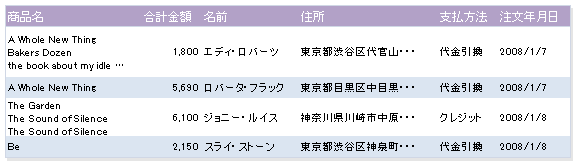
これをリレーショナルデータベースのテーブル構造に置き換えるには、データの整合性が維持しやすいようにデータのグループを分離し、リレーションを作成する必要があります。上記のようになテーブル構造だと、顧客情報は何かを購入するたびに登録されることになり、住所が変わったり名前が変わったりした場合の処理が難しくなります。また、商品名フィールドには複数の商品名が登録されているので、あとで統計を作成したりデータを検索する際に問題になります。このように正規化が行われていないデータベースは、データ領域を余計に消費し、パフォーマンスにも悪影響を与えます。
リレーショナルデータベースでは、単純にデータを保存できるだけではその威力を発揮することができません。検索や統計の作成、データ内容の変更といった幅広い要望に答えられる必要があります。そのような要望に答えられるテーブル構造を作成し、チェックするためのテクニックがリレーショナルデータベースの正規化です。
正規化のステップ
正規化の主な作業は、テーブルにキーを設定し、余分なフィールドを整理し、適切にテーブルを分割することです。これらの作業はいくつかのステップに分けて行われます。正規化には、第1正規形、第2正規形、第3正規形、ボイスコッド正規形、第4正規形、第5正規形といったステップがあります。多くのリレーショナルデータベース管理システム (RDBMS) は、論理的なデータベース設計とデータを格納する物理的な実装方法とが十分に分離されていないこともあり、完全に正規化するとパフォーマンスによくない影響を与える可能性があります。一般的には第3正規形まで正規化が行われます。
詳しくは後述しますが、第1正規形から第3正規形の処理内容を紹介します。
- 第1正規形
- キーを設定し、フィールドの繰り返しグループを別テーブルに分離、導出項目を取り除く。
- 第2正規形
- 部分関数従属性を別テーブルに分離。
- 第3正規形
- 推移関数従属性を別テーブルに分離。
第1正規化
第1正規形の作業は、フィールドの繰り返しグループを別テーブルに分離し、導出項目を取り除くことです。具体的には、正規化を行っていないテーブルに対し、次のような処理を行います。
フィールドの繰り返しを避ける
まず、1件のレコードに、フィールドの繰り返しや、フィールド中に複数のデータがある場合、そのフィールドを別レコードとして分離します。
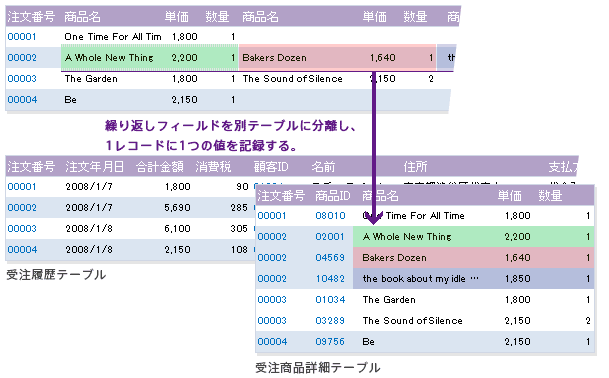
分割後の2つのテーブルには、同一レコードの中で同じフィールドが複数あったり、1つのフィールドに複数の値が登録されるといった問題が解消されています。上記では、注文された商品情報の詳細を別のテーブルとして分離し、注文番号で2つのテーブルにリレーションを作成しています。注文番号は受注履歴テーブルのプライマリキーであり、受注履歴テーブルと受注商品詳細テーブルにリレーションを作成する外部キーです。
プライマリキーは次の規則に従ったフィールドです。
- 同じフィールドの中でユニークな値を保障します。
- NULL値は登録できません。
- 生成から削除まで値は変更できません。
プライマリキーは名前やそのほかのフィールドを割り当てるのではなく、プライマリキー専用のフィールドを用意します。正規化には、プライマリキーと外部キーは必須です。
導出フィールドの削除
『導出フィールド』とは、他のフィールドの値から自動的に値を算出することができるフィールドのことです。たとえば、[消費税]フィールドの値は、[合計金額]に消費税5%として0.05をかけると値を求めることができます。この[消費税]フィールドのようなフィールドを、導出フィールドと呼びます。正規化を行う際は、このような余分なフィールドを削除していく必要があります。
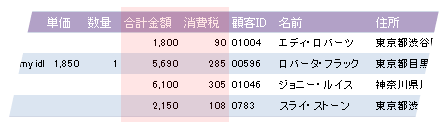
次の図にあるように、[消費税]フィールドは余分なので削除します。[合計金額]も商品の単価と数量で求めることができるので、不要です。ただし、最終的な合計金額などは、削除せずに残すことも検討したほうがよいでしょう。商品の単価が変わる前に購入されたデータが勝手に新しい価格で計算し直されたりすると、問題になります。変更などのことも考慮して、フィールドを整理していく必要があります。
導出フィールドの合計金額と消費税を削除
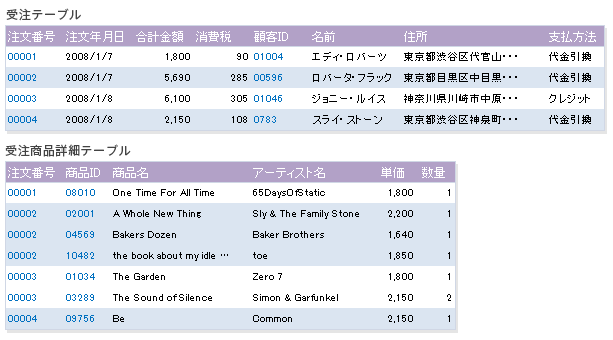
第1正規化では、商品情報の繰り返し問題を解消するために、テーブルを分離し、導出フィールドを削除しました。その結果、次のようなテーブルになります。
第2正規化
第2正規化は、部分従属するフィールドを分離し、候補キーが決まれば、その他のフィールドも決定できるように正規化します。部分従属とは、1つの候補キーによって値が決定する関係です。
たとえば、受注商品詳細テーブルには、候補キーの[商品ID]だけに従属する[商品名]、[アーティスト名]、[単価]というフィールドがあります。これらのフィールドが部分従属です。第2正規化では、この部分従属にあたるフィールドを別のテーブルとして分離します。

なぜ分離する必要があるかというと、受注商品詳細テーブルでは、同じ商品が購入されるたびに同じ商品情報が登録されるため、商品名の変更などがあった場合は、登録されている全てのレコードを変更しなければなりません。また、注文があって初めて商品情報が記録されるため、注文が無い商品はデータベースに記録されません。部分従属するフィールドは、別のテーブルに分離して専用に管理するのがベストです。
受注商品詳細テーブルから[商品ID]に従属する部分従属フィールドを別テーブルに分離すると、下記のようになります。
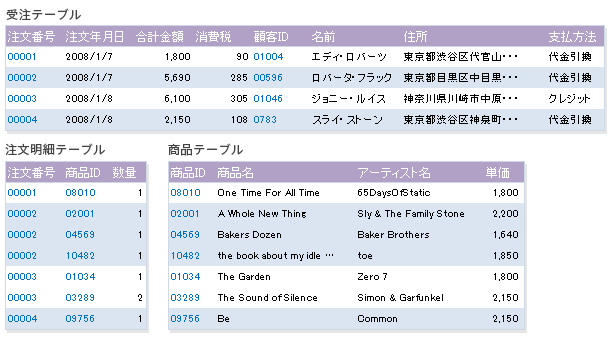
第3正規化
第3正規化では、プライマリキーに直接従属しない、推移従属しているフィールドを分離します。推移従属とは、プライマリキー以外のフィールドに従属している関係を指します。第2正規化で部分従属を分離し、第3正規化で推移従属を分離します。これで、各テーブルは完全従属しているフィールドで構成されることになります。
第2正規化の状態にあるテーブルには、そのテーブルとは直接関係のないフィールドがあります。たとえば、受注テーブルに[名前]、[住所]フィールドがありますが、これらの顧客情報は別テーブルに分離できます。
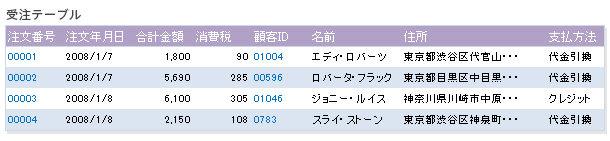
顧客情報を購入履歴テーブルから切り離し、新たに顧客テーブルを用意しました。これにより、購入履歴テーブルから商品テーブル、顧客テーブル、購入商品テーブル全ての値を効率よく参照し、完全に重複を排除しています。
顧客情報を受注テーブルから切り離し、新しく顧客テーブルを作成します。
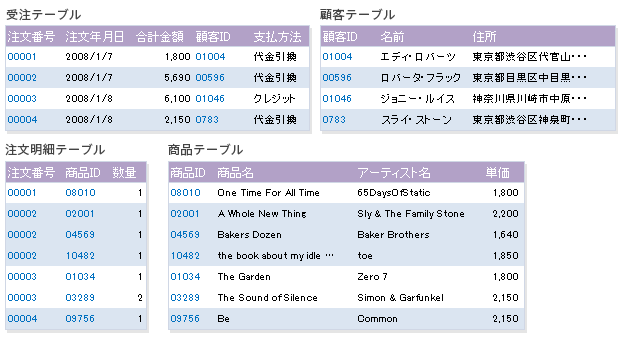
ここでは、受注テーブル、顧客テーブル、注文明細テーブル、商品テーブルに分離しただけですが、実際はアーティスト情報を取り出してアーティストテーブルに分離したり、アーティストが所属するレーベルなどもレーベルテーブルに分離することができます。ただし、第3正規化をあまり厳密に適用しすぎるのは、運用時のパフォーマンスや作業効率に悪い影響を与える可能性があります。たとえば、1つのレーベルしか扱わない場合は、わざわざレーベル情報を分離する必要はないかもしれません。また、顧客情報の住所を住所テーブルとして分離する必要性もほとんどありません。分離することは可能ですが、分離した恩恵が望めない場合や、パフォーマンスに悪影響を与えそうな場合は、わざわざ分離する必要がないこともあります。
第3正規形は、テーブルの利用形態などをじっくりと考えてから、データの変更頻度や重要度によってケース・バイ・ケースに適用するのが現実的でしょう。
その他の正規形
BCNF (Boyce Codd Normal Form) と呼ばれる第4正規形や、第5正規形が存在しますが、実用的な設計とはみなされていません。機能的にも影響が限られていますので、ほとんどの設計では適用されていません。